
Abstract
Even trained mainly on images, we discover that pretrained diffusion models show impressive power in guiding sketch synthesis. In this paper, we present DiffSketcher, an innovative algorithm that creates vectorized free-hand sketches using natural language input. DiffSketcher is developed based on a pre-trained text-to-image diffusion model. It performs the task by directly optimizing a set of Bézier curves with an extended version of the score distillation sampling (SDS) loss, which allows us to use a raster-level diffusion model as a prior for optimizing a parametric vectorized sketch generator. Furthermore, we explore attention maps embedded in the diffusion model for effective stroke initialization to speed up the generation process. The generated sketches demonstrate multiple levels of abstraction while maintaining recognizability, underlying structure, and essential visual details of the subject drawn. Our experiments show that DiffSketcher achieves greater quality than prior work.
Methodology
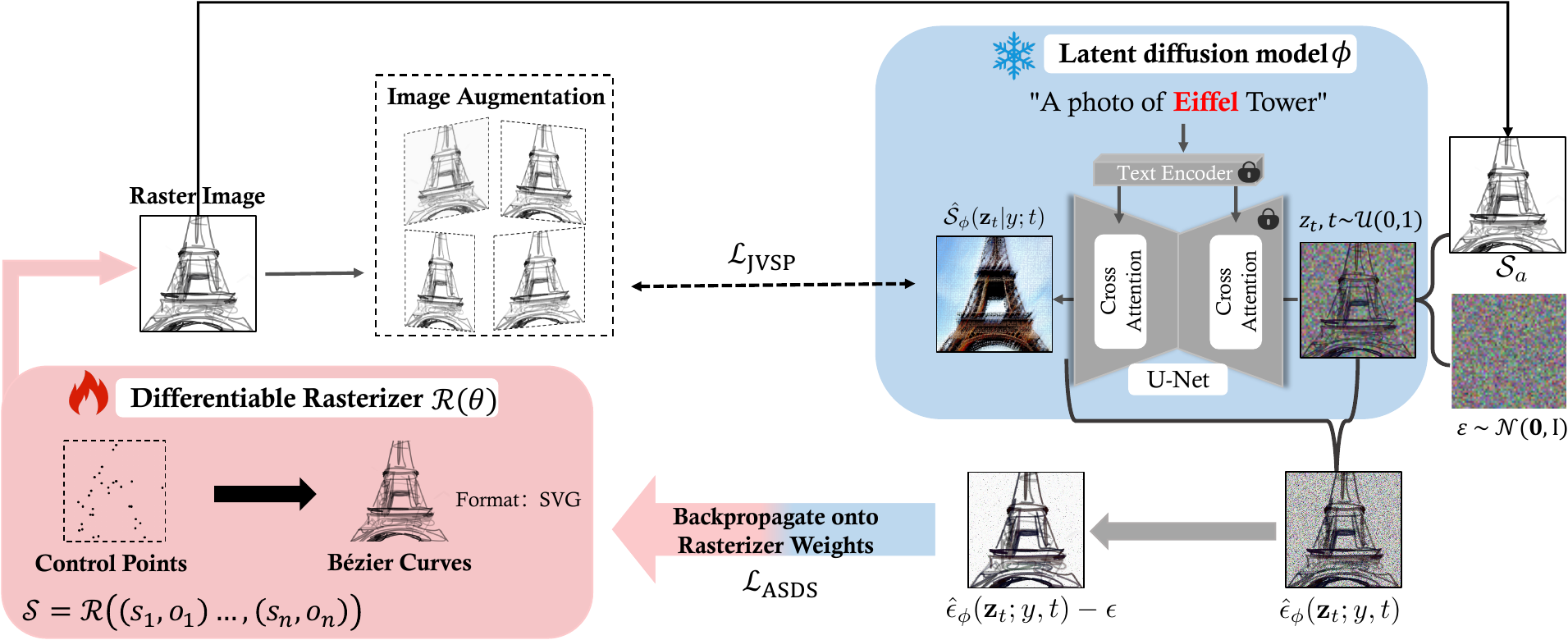
DiffSketcher generates free-hand sketches from a text prompt such as "A photo of Eiffel Tower". To synthesize a sketch that matches the given text prompt, we optimize the parameters of the differentiable rasterizer R that produces the raster sketch S, such that the resulting sketch is close to a sample from the frozen latent diffusion model (the blue part of the picture). Since the diffusion model directly predicts the update direction, we do not need to backpropagate through the diffusion model; the model simply acts like an efficient, frozen critic that predicts image-space edits.
Demo

More Results



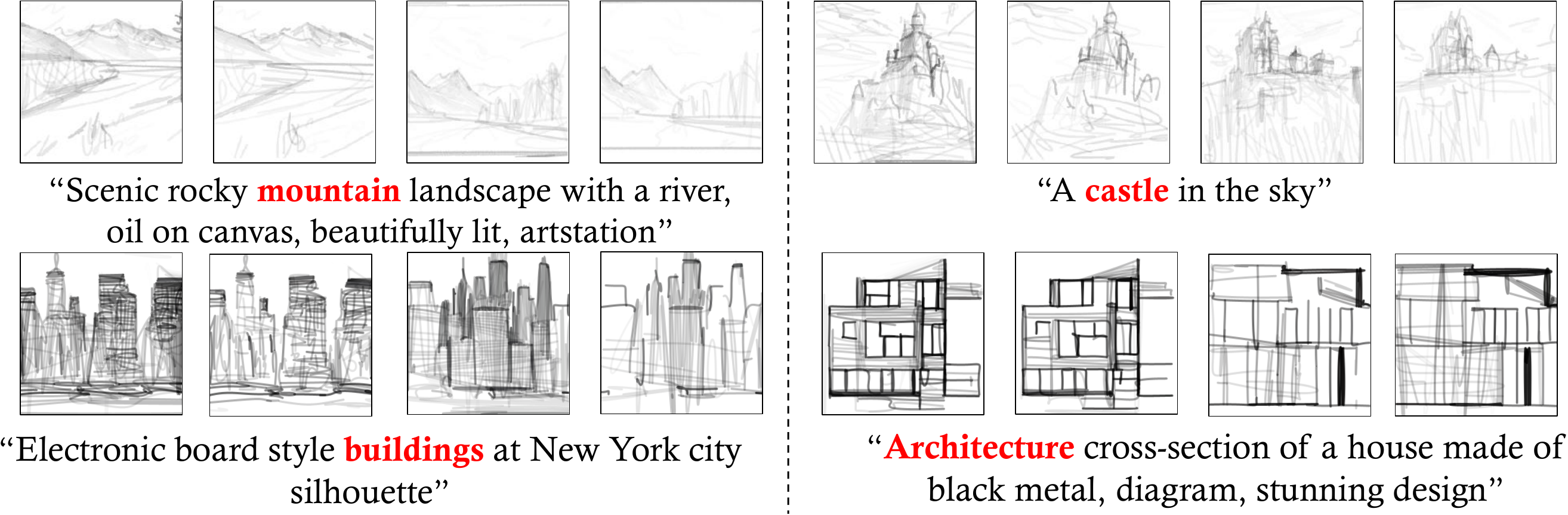
Painterly Rendering
Colorful Results
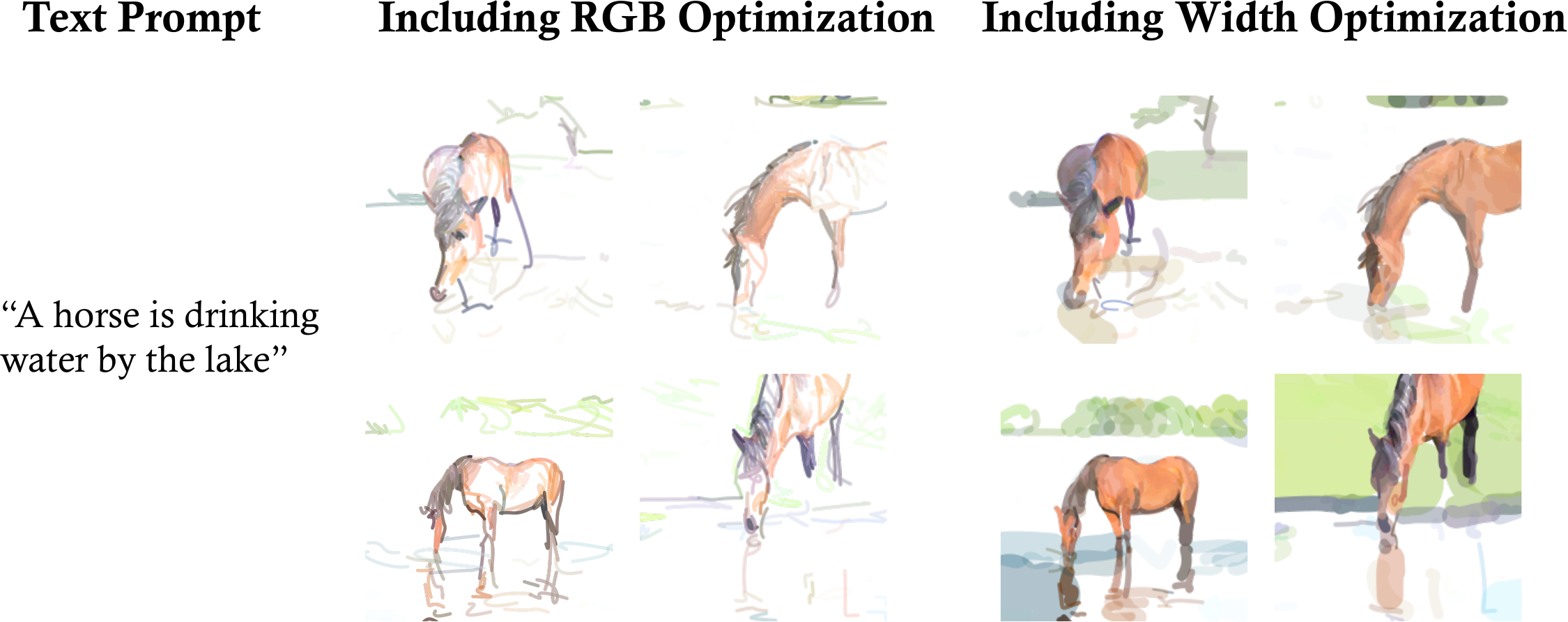
Oil Painting

style Transfer

Citation
@inproceedings{xing2023diffsketcher,
title={DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion
Models},
author={Xing, Ximing and Wang, Chuang and Zhou, Haitao and Zhang, Jing and Yu, Qian and
Xu, Dong},
journal={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=CY1xatvEQj}
}